Rill 0.39 - Vacations, spending time away from keyboard and new ways of filtering
⚡ Rill Developer is a tool that makes it effortless to transform your datasets with SQL and create fast, exploratory dashboards.
To try out Rill Developer, check out these instructions and join us over on Discord to meet the team behind the product as well as other users!
After a couple of days of holiday break we are back at it again with yet another release. This time around it's a smaller one as we have been busy digesting holiday food and putting away all of those Christmas decorations (who are we kidding, they will still be up come February...)
Also a big shout-out to our community members Fred, Christian and Frederik for contributing to the project!
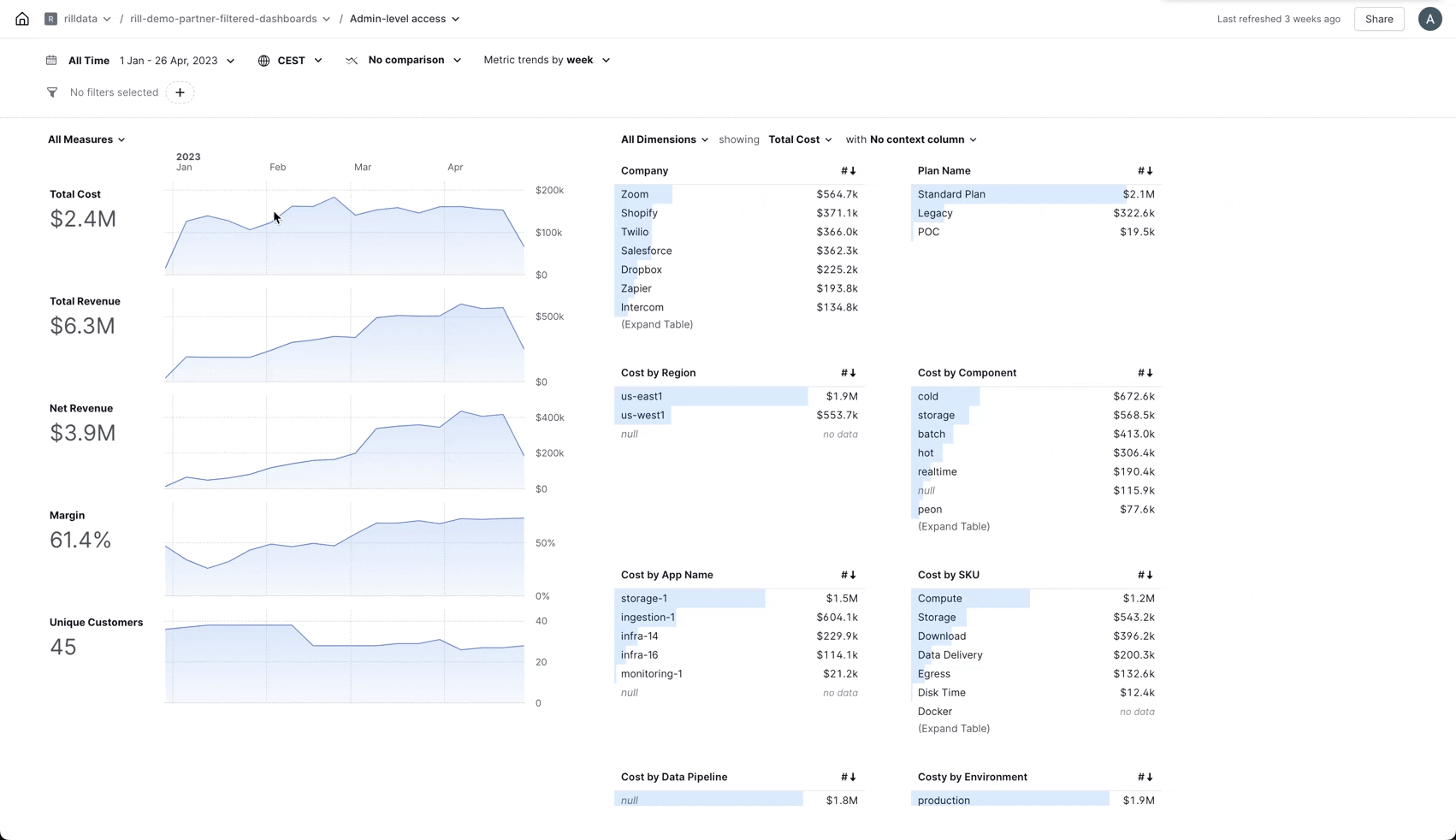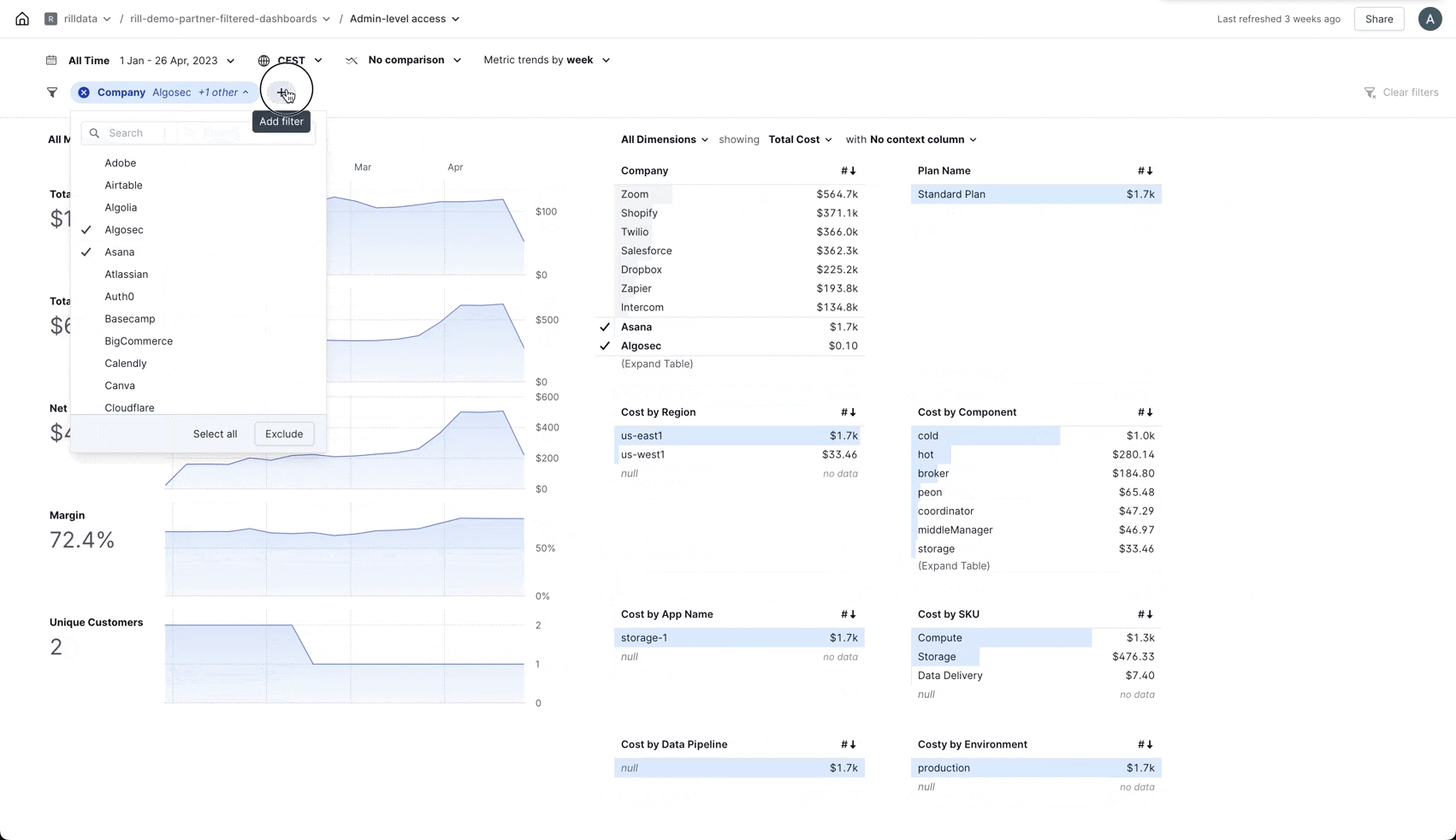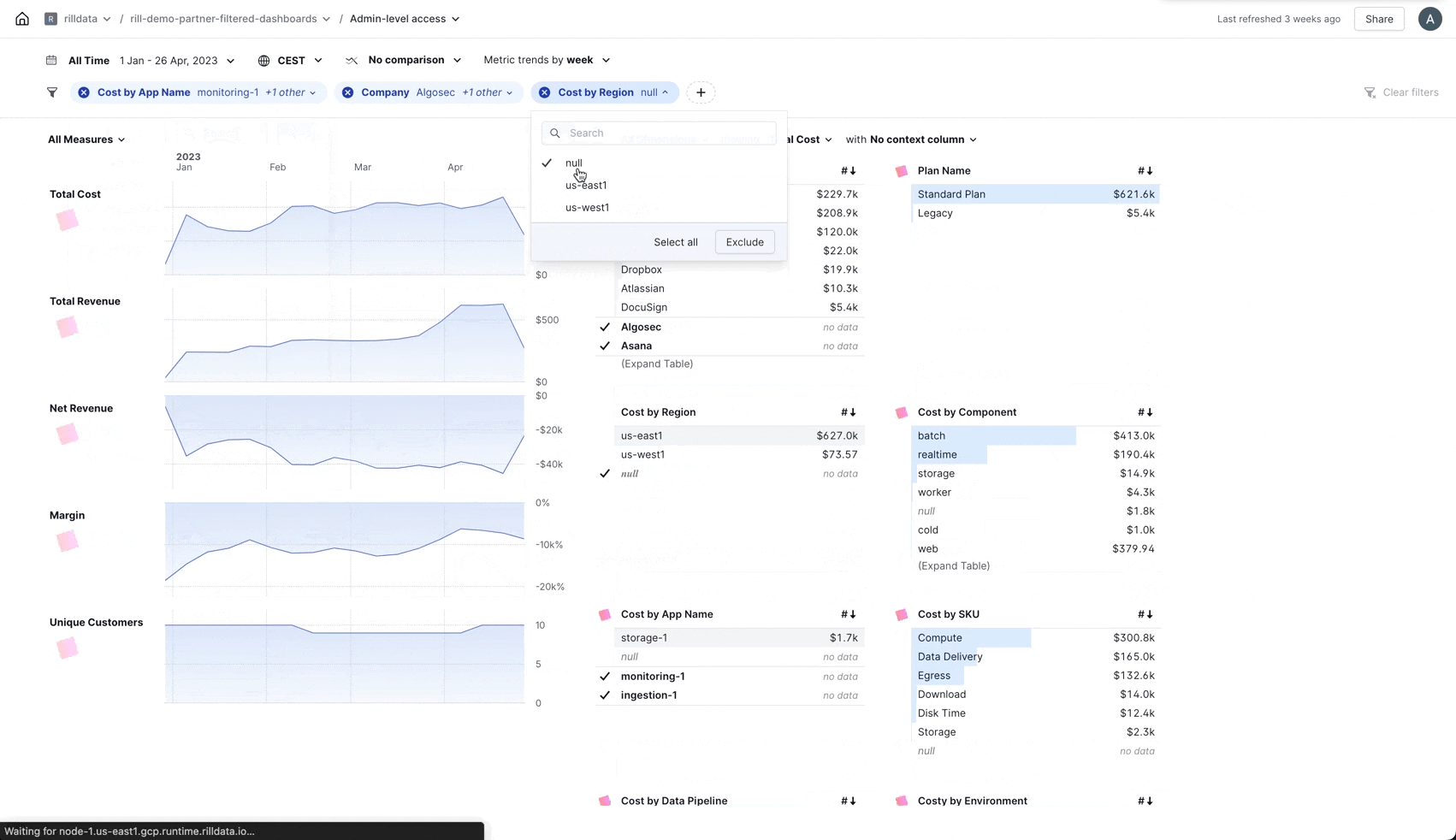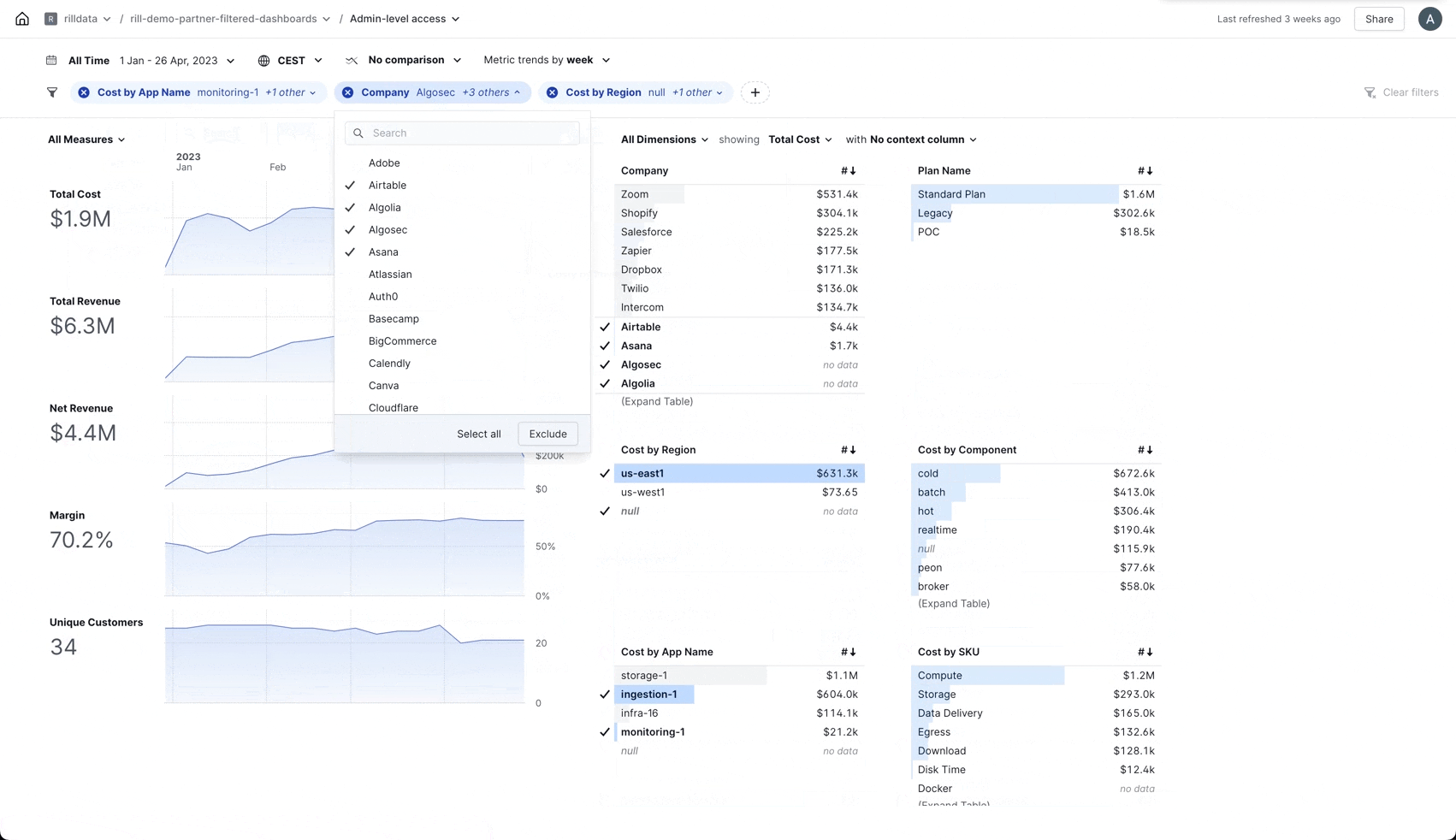
Add Filter
You can now add new filters directly from the filter bar.
As we are adding more and more areas to Rill the need to be able to quickly add a new filter without having to go back to the Explore overview became apparent and... now you can!
Auto-suggestion of models
Rill Developer will now auto-suggest model names as part of our auto-completion when writing SQL.
This should make it easier to write transformation steps within projects with a large number of models.
Daylight savings support
We have added DST support for our timeseries charts to properly handle time-jumps
Bug Fixes and Misc
- Updated project status page to reflect both the most recent time when a source or model has been refreshed and the most recent time the project files in Github have been synced.
- Added further hardening and resiliency in the runtime backend to prevent potential OOM or deadlock scenarios related to DuckDB.
- Added dimension name and percent of total to charts.
- Added further consistency in colors being used in themes.
- Fixed scenario where the horizontal splitters in the UI could overflow its parent container.
- Improved the responsiveness and rendering of timeseries charts.
- Improved error handling and hardening related to saved views on dashboards.
- Addressed a bug where searching in a dimension table would sometimes return a 400 error in very specific scenarios.
- Added support for templating and use of variables in source YAML files.
- Improved the design of our Scheduled Report dropdown menus.
- Fixed a bug when using the "View as" functionality in the Cloud UI.
- Added clearer messaging when autogenerating dashboards.
- Added ability to define arbitrary, non-aggregrate dimension expressions via the
expressionproperty in the dashboard YAML. - Added support to resize the Model Data dashboard component / view in the Rill Developer UI.
- Fixed bug related to the Shift-click to copy functionality not working as expected.