Tutorial: BigQuery Ingestion
Overview
To import data form BigQuery, you will first need to grant Rill access to your BigQuery data. Once that is complete, you'll ingest the data via the Druid console following the same steps shown in Druid Data Ingestion and Druid Optimization During Ingestion
Grant Rill access to your BigQuery project
Starting in Rill, your workspace has a Google Service Account associated with it. You will then go to your BigQuery project and add that Google Service Account as a member with BigQuery Data Viewer permission. To keep everything in one place for this tutorial, we'll walk you through granting access here. These instructions call also be found here.
Find your Google Cloud Service Account by logging into Rill and clicking on Integrations. Your Google Cloud Service Account will be displayed. It will be of the form
organization-workspace@rilldata.iam.gserviceaccount.com.Go to your Google Cloud Console and select the project to which you want to grant access.

Open the sidebar menu by clicking the 3 lines button in the top left, then choose IAM & Admin then click on IAM https://console.cloud.google.com/iam-admin/iam
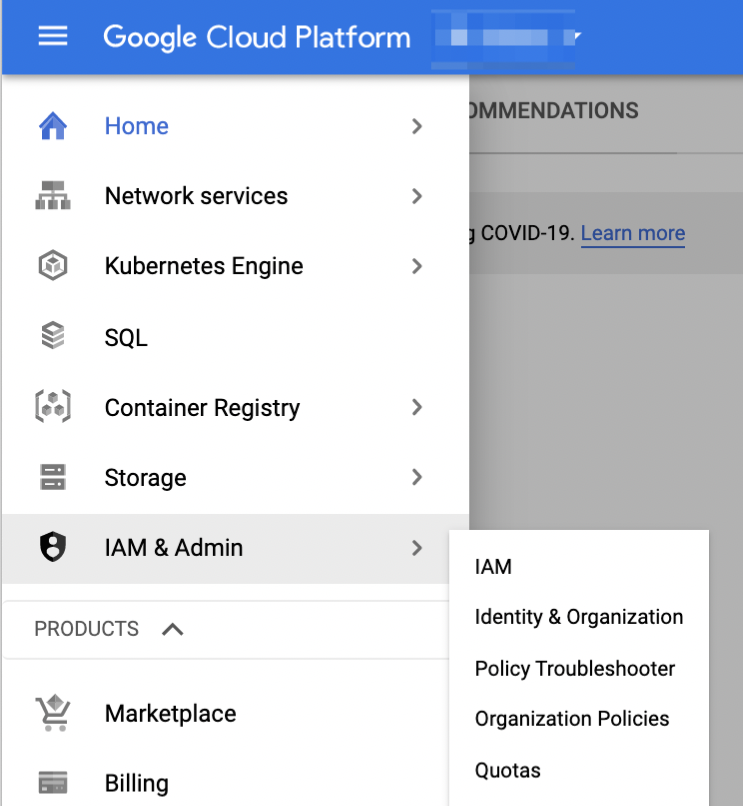
In the IAM menu click the ADD button. This will display a form where you can input the service accounts that can access your project and the permissions with which they can access it.
In the New members field, enter your google service account, found in step 1.
Select the role
BigQuery Data Viewer. This will permit Rill to fetch your projects tables into BigQuery.Click on save.
Ingest a BigQuery table into Rill
Now that you've given Rill permission to access your BigQuery data, you'll load your BigQuery dataset into Rill.
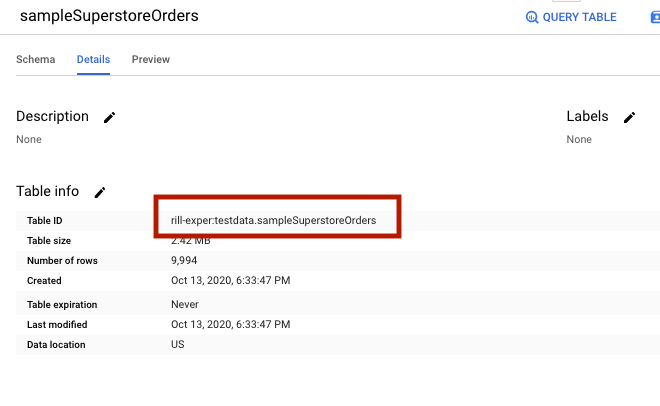
Go to your BigQuery dataset, select the table you want to load, and click on Details to find the table id. Copy the table id into your clipboard. You will use this table id when you load your data so save it away - either keep it in your clipboard or copy it into a document.
In Rill, click on
Druid ConsoleThis is a button in the upper right of RCC. A new tab will be created for you that displays the Druid console. You'll see
Load Data,Ingestion, andQuerytabs. If you don't see theLoad Datatab, you will need to ask your Rill admin for Editor privilege.Click on the
Load Data.If you see a screen with two buttons that say
Start a new specandContinue from previous spec, chooseStart a new spec.You should see a variety of connector tiles. Click on the
Google BigQuerytileClick on
Connect Data**Paste the table id from BigQuery that you copied into your clipboard into the Table ID field and click
Apply.You should see a preview of your data
Proceed through Druid Data Ingestion, clicking
Nextin the bottom right to step through the various ingestions stages. Remember to name your dataset appropriately in thePublishstageSubmit your ingestion spec in the final stage. When the status of the job says
Success, click on theQuerytab at the top to go to the Druid SQL console and use SQL to query your new dataset.