Confluent/Apache Kafka
Setup Instructions
Follow the instructions below to grant Rill access to your Apache Kafka Cluster and the data on a given topic within the cluster. Proving access to a cloud provided service, such as Confluent Cloud, is easier due to all of the connection and security is already taken care of for you. If you are using a self-manage cluster, ensure security and encryption are configured accordingly.
The following 3 scenarios are covered, and understand that Apache Kafka is designed to work within almost any Enterprise environment allowing for a variety of unique configurations. Work with your engineering team and Rill Data for ensuring your configuration and setup is performant and secure.
- Confluent Cloud
- Private Kafka Cluster
- VPC Kafka Peering
- Public Kafka Cluster
- AWS Kinesis
Confluent Cloud
Confluent Cluster is inherently secure and accessible. The communication aspects with Confluent Cloud can be done in a few minutes. The main importance is to determine the level of accessibility for the credentials you will be using from the Rill platform for accessing the Confluent Cloud Cluster.
The concepts here apply to other Apache Kafka SaaS offerings, even though the means to access them might be different. Please reach out if you have any questions integrating with your Apache Kafka SaaS provider.
Credentials
The first step is to create a security key you can use from Rill Data for accessing your Kafka. Select a Granular access key to reduce exposure. You can use an existing key and even an actual account when creating the client API access.
Create Key and Secret
Select "+ Add Key" from the "Cloud API Keys" menu option and create a non-admin account. Create a service account unique to accessing data from RillData and be sure to download and secure the client key and secret for use from RillData Druid Ingestion.
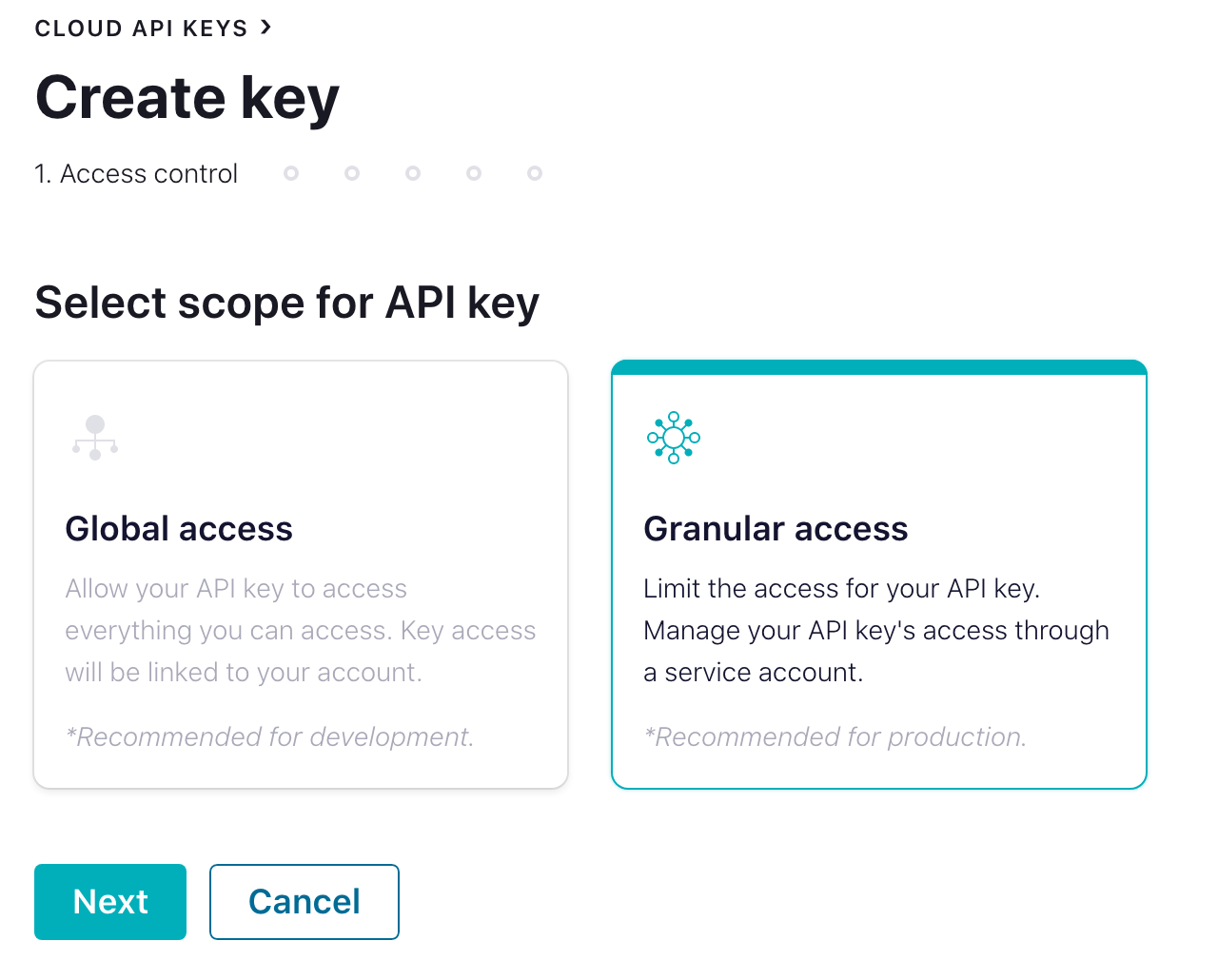
It is recommended to create a unique service account, so your access control can be uniquely established for access from Rill Data into your Confluent Cloud Kafka Cluster.
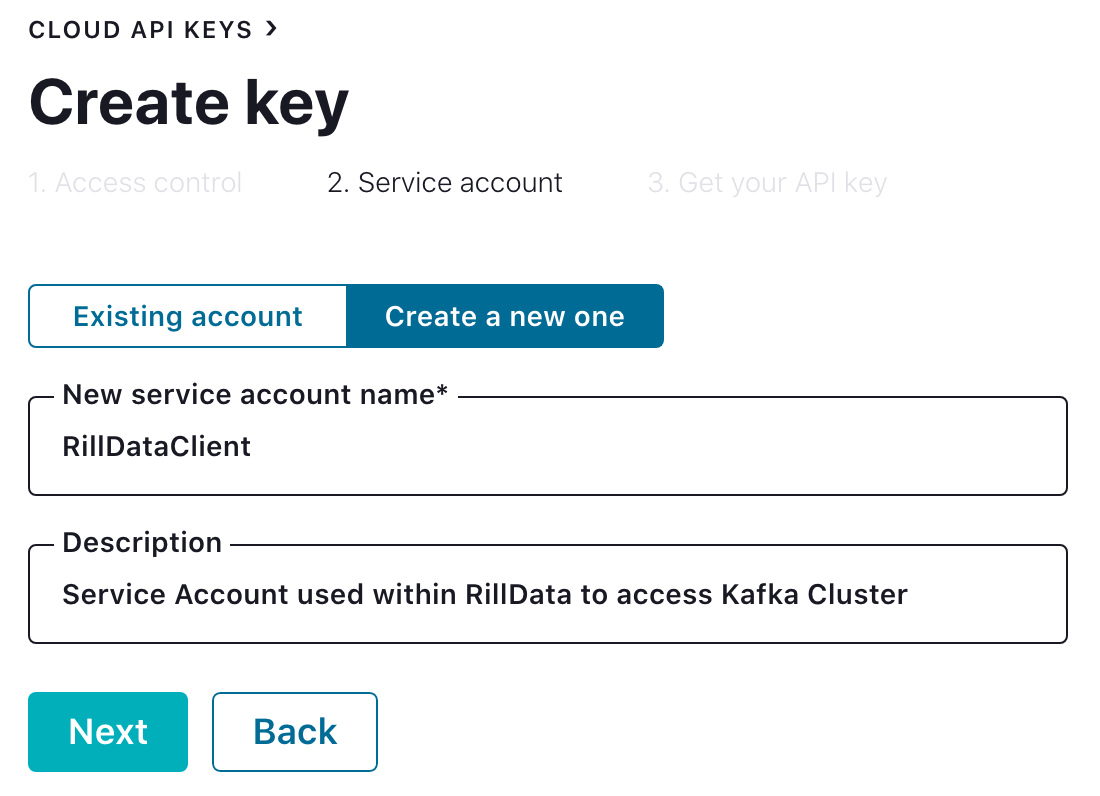
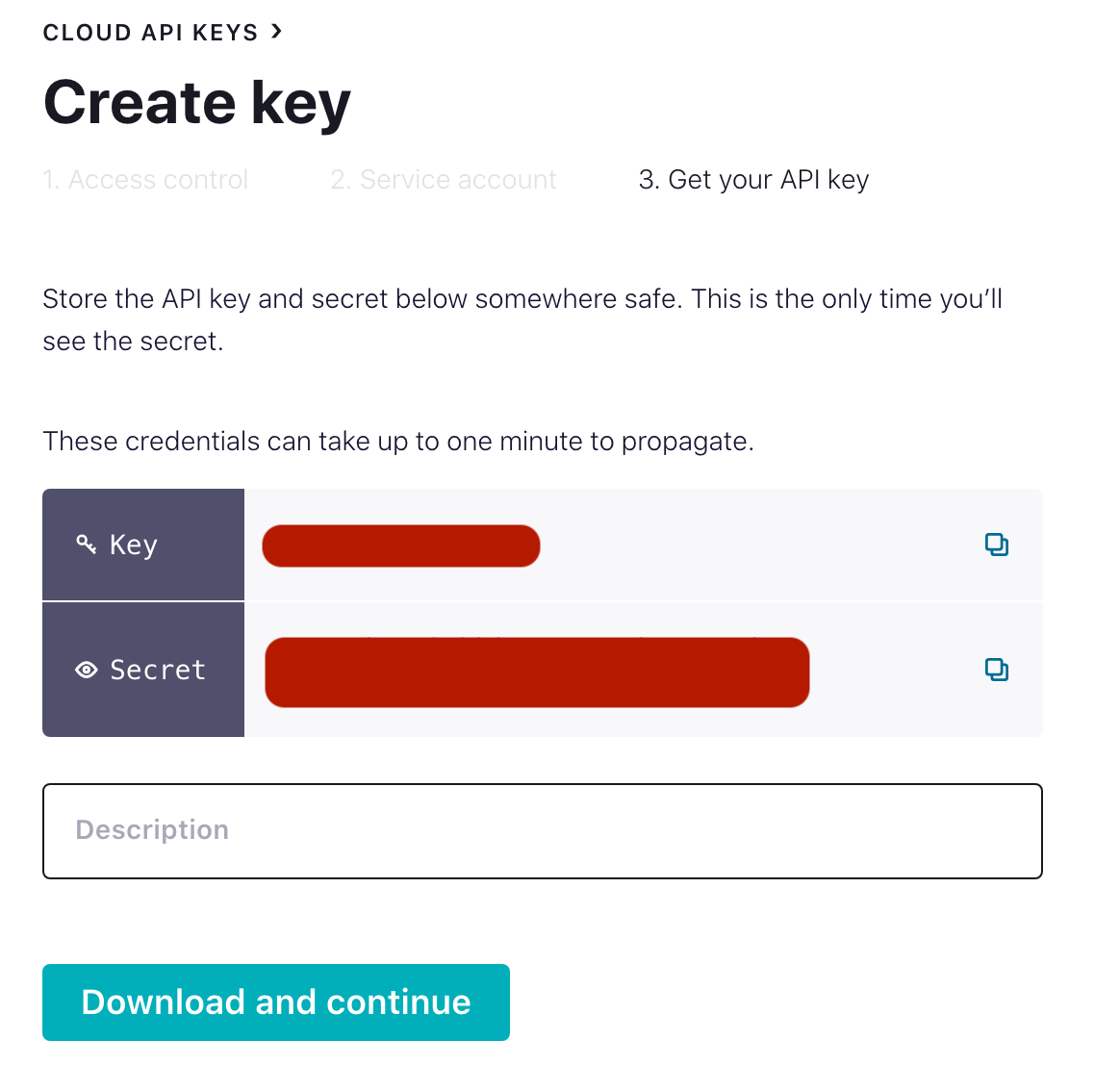
If you fail to download or lose the key/secret a new key/secret will need to be generated.
Create Cluster API Access
Rill Data manages the Kafka topic offset internally, so the Apache Kafka Connection only needs topic read access.
The best way to provide Rill access to your cluster is through Granular access with the above service account.
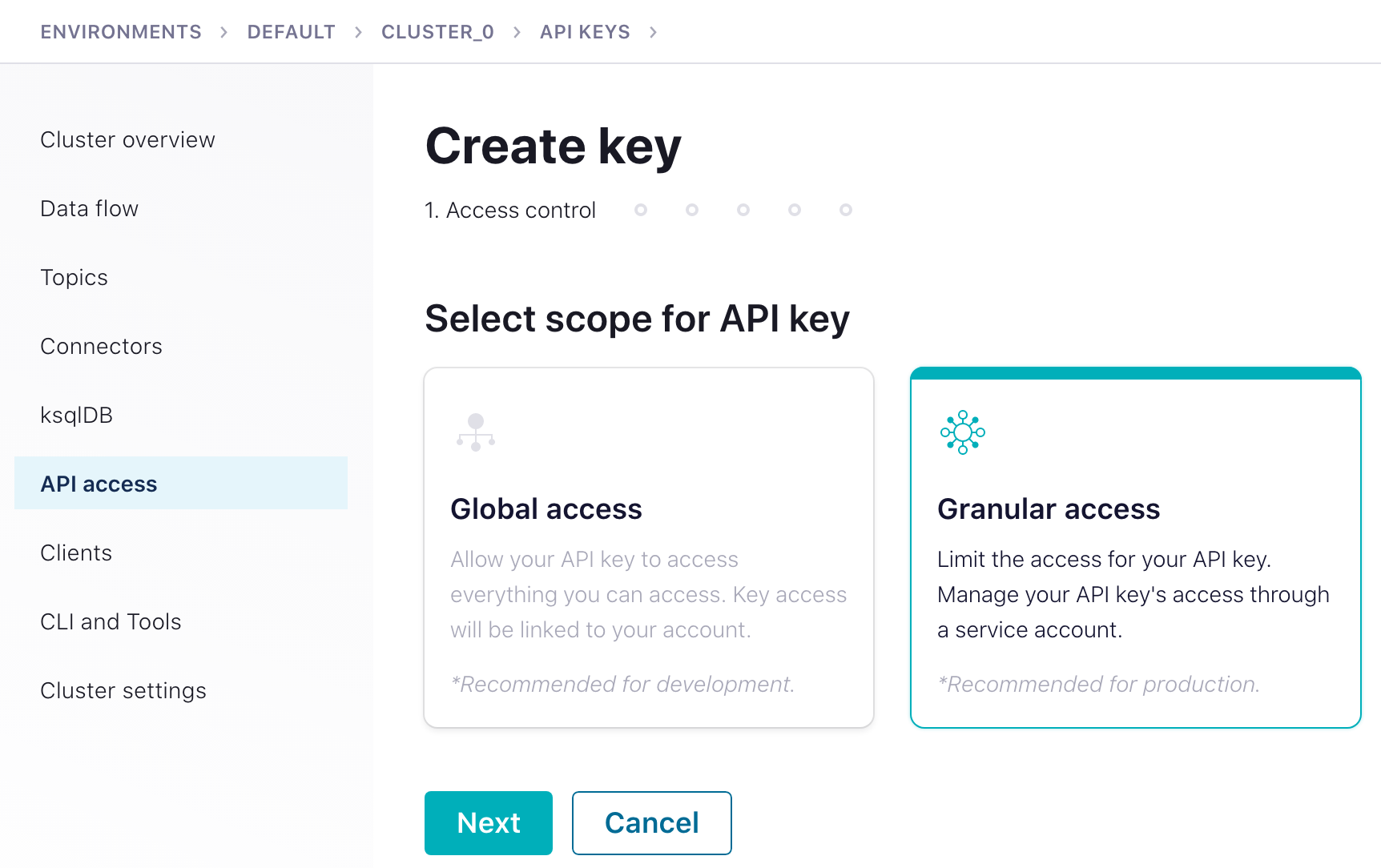
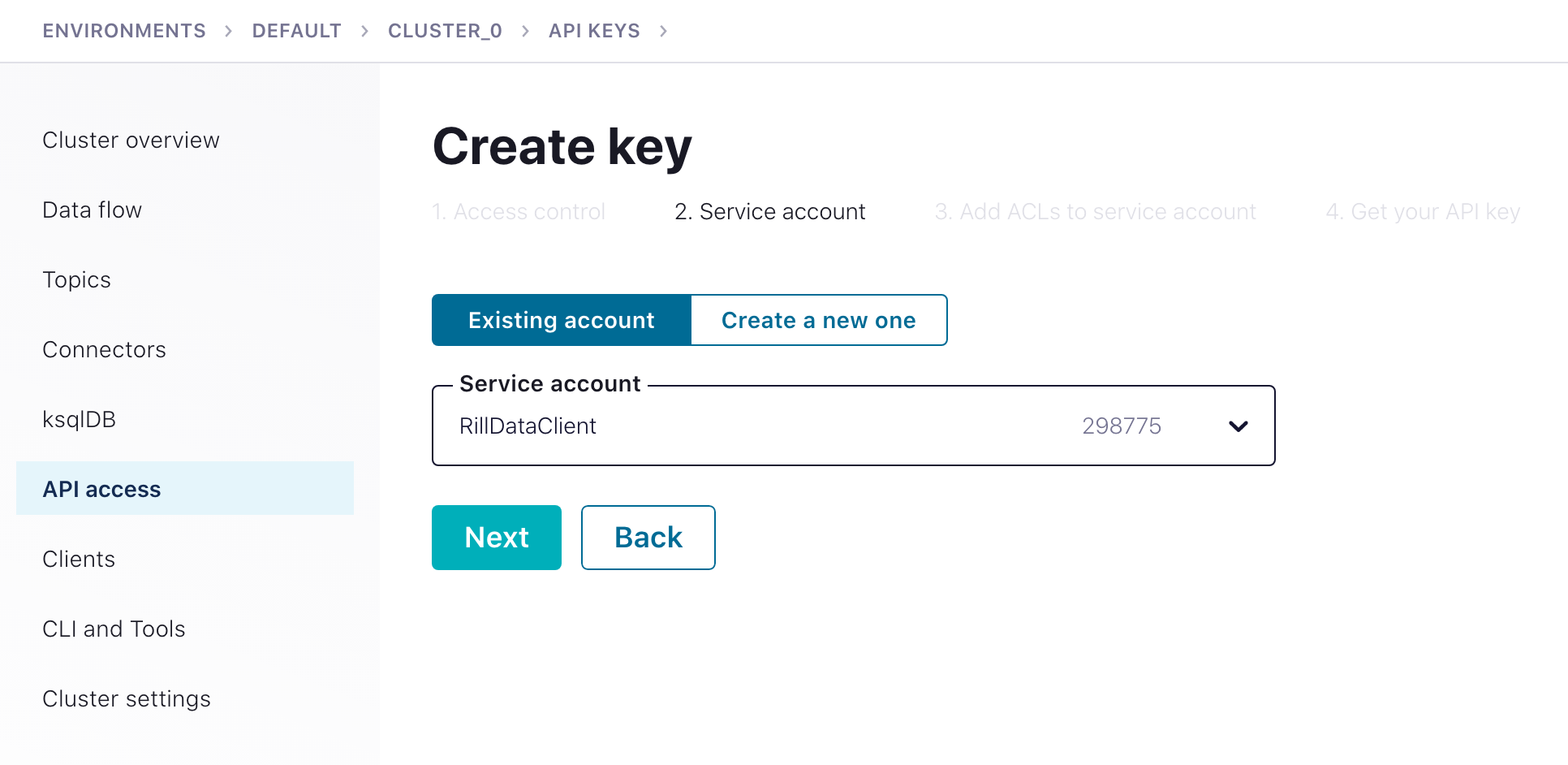
Ideally, using a topic-name prefix is preferred; since it minimizes the number of ACLs rules you need to create and manage for the API access key/secret.
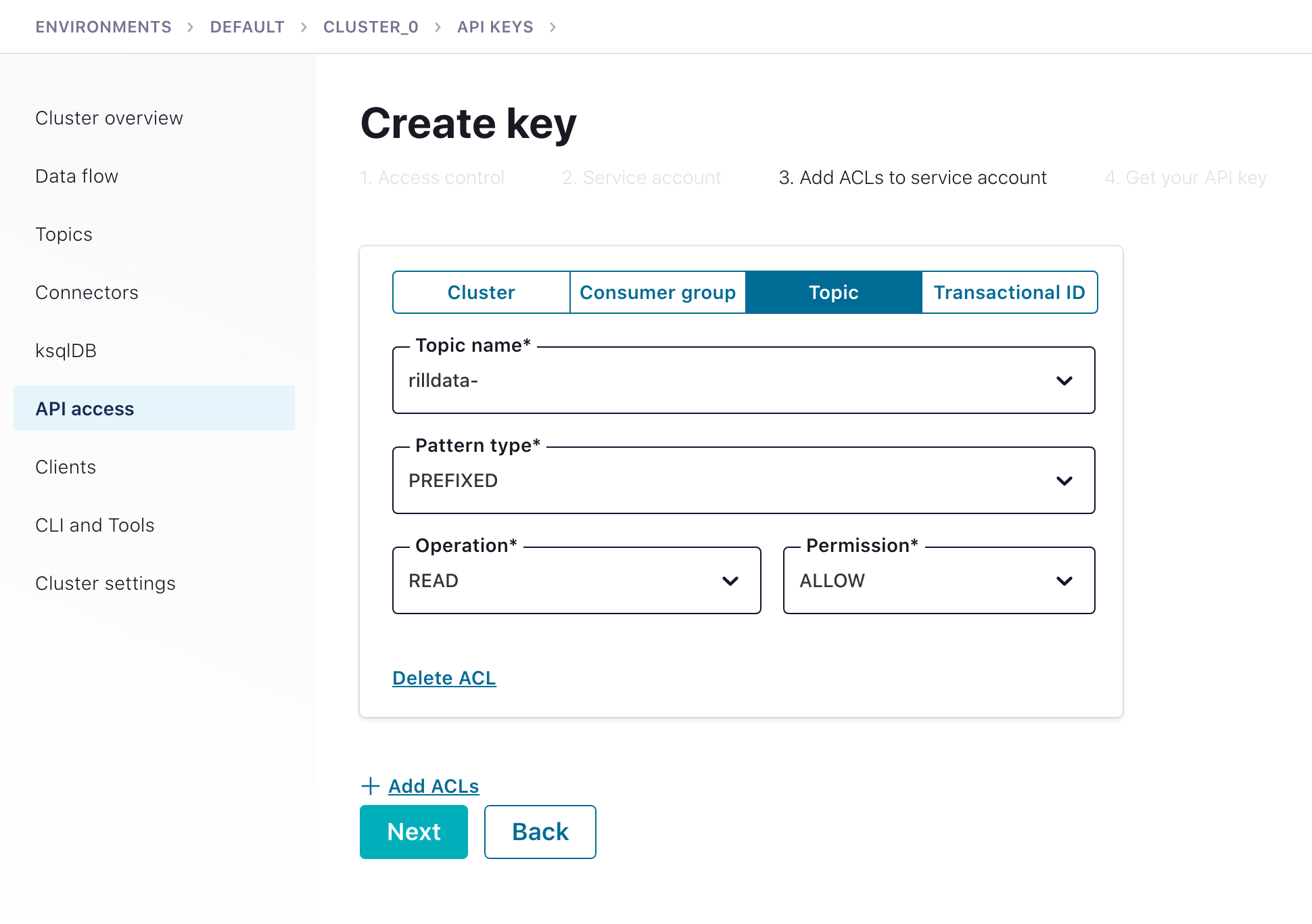
Data Ingestion
Follow the Ingestion Tutorials for all of the nuances for getting the data into Rill Data as needed. The key aspects for Confluent Cloud Ingestion are through establishing the bootstrap-server, customer properties for access, and the topic to consumer from.
- Bootstrap servers: Cluster's Broker and Port
- Topic: The Kafka Topic
- Consumer properties: At minimum the properties needed to access cluster with key/secret
- Where should the data be sampled from? Start of stream or End of stream
see ioConfig example shown from a complete ingestion specification for pulling data from Kafka, insert the key and secret into the JAAS config.
"ioConfig": {
"type": "kafka",
"consumerProperties": {
"bootstrap.servers": "{{ CLUSTER_HOSTNAME }}:9092",
"security.protocol": "SASL_SSL",
"sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username='{{ CLIENT_KEY }}' password='{{ CLIENT_SECRET }}';",
"sasl.mechanism": "PLAIN"
},
"topic": "rilldata-sourcedata",
"inputFormat": {
"type": "json"
},
"useEarliestOffset": true
}
Private Kafka Cluster
When connecting to a private Apache Kafka Cluster, accessibility and security are the most significant configuration areas. Rill Data connects directly to the Kafka Cluster as a Kafka Client and will access your cluster as any other consumer client.
- For Apache Kafka to be highly performant, the client API communicates directly to the active Kafka broker for a given partition.
- Configure your cluster to where the brokers are each individually accessible from the Rill services.
- Apache Kafka has the server property advertised.listeners to ensure that the client has the correct information to communicate with an individual broker.
When configuring your Kafka Cluster, ensure it can be accessible from the Rill by establishing a VPC. An example setup is shown via AWS Private Link below. AWS Private Link allows exposure of the Kafka brokers over Network Load Balancer using VPC Endpoints. The network packets always retain within the AWS Network.
AWS Private Link
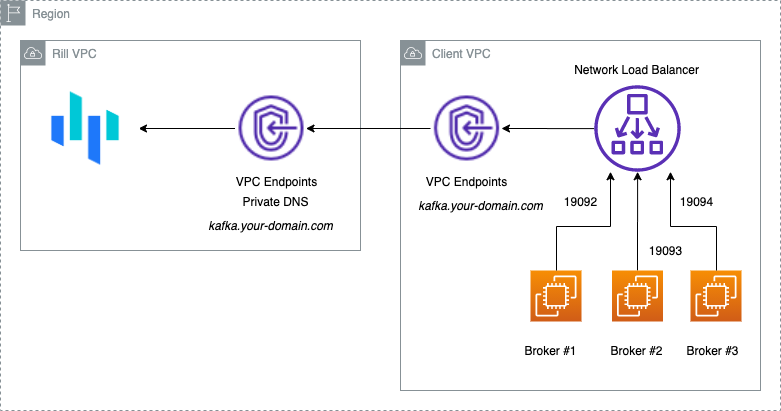
Kafka EXTERNAL advertised listeners should match the DNS name configured.
Kafka Configurations
Network Load Balancer will expose all the brokers with different ports. Each broker can have an incremented port for EXTERNAL access, e.g. 9092, 9093, and 9094)
listener.security.protocol.map=EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
advertised.listeners=PLAINTEXT://:9092,EXTERNAL://${PRIVATE_DNS_NAME}:${INCREMENTED_PORT}
## Eg:
# Broker #1
# advertised.listeners=PLAINTEXT://:9092,EXTERNAL://private-kafka.rilldata.com:19092
# Broker #2
# advertised.listeners=PLAINTEXT://:9092,EXTERNAL://private-kafka.rilldata.com:19093
# Broker #3
# advertised.listeners=PLAINTEXT://:9092,EXTERNAL://private-kafka.rilldata.com:19094
AWS Private Link using Cloud Formation
Open AWS Cloud formation to create a new Stack. https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/create/template
Use Amazon S3 URL: https://s3.amazonaws.com/cf-templates.rilldata.com/rilldata-private-link.yaml
Ref: AWS Private Link
VPC Peering
- Since the cluster is private, setting up SSL may not be needed -- as it would depend on your corporate policies.
- Authentication: create a user to be used for consuming
- Authorization: allow the user to consume from a specific topic
- Do VPC network peering
- Make sure every broker’s advertised endpoint is accessible from a consumer.
- Set up the consumer by storing the user’s credentials into the consumer’s configuration file.
Public Kafka Cluster
By default, there is no encryption, authentication, or ACLs (access control list) configured. Any client can communicate to Kafka brokers via the PLAINTEXT port.
It is critical that access via this port is restricted to trusted clients only. Network segmentation and/or authorization ACLs can be used to restrict access to trusted IPs in such cases.
If neither is used, the cluster is wide open and can be accessed by anyone.
- Enable SSL encryption: SSL uses private-key/certificates pairs which are used during the SSL handshake process.
- Authentication & Authorization: Create a user to be used for consuming and allow the user to consume from a specific topic
- Make sure every broker’s advertised endpoint is accessible from a consumer.
- Set up the consumer by adding broker’s certificate into a trust store and storing the user’s credentials into the consumer’s configuration file
AWS Kinesis
We can provide access to the Kinesis stream through an IAM Role which will be assumed by the Rill Data AWS Account to gain the access.
arn:aws:iam::248432388601:root
Using Cloudformation Console
Open AWS Cloudformation to create a new Stack. https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/create/template
Use Amazon S3 URL:
https://s3.amazonaws.com/cf-templates.rilldata.com/rilldata-kinesis-access.yaml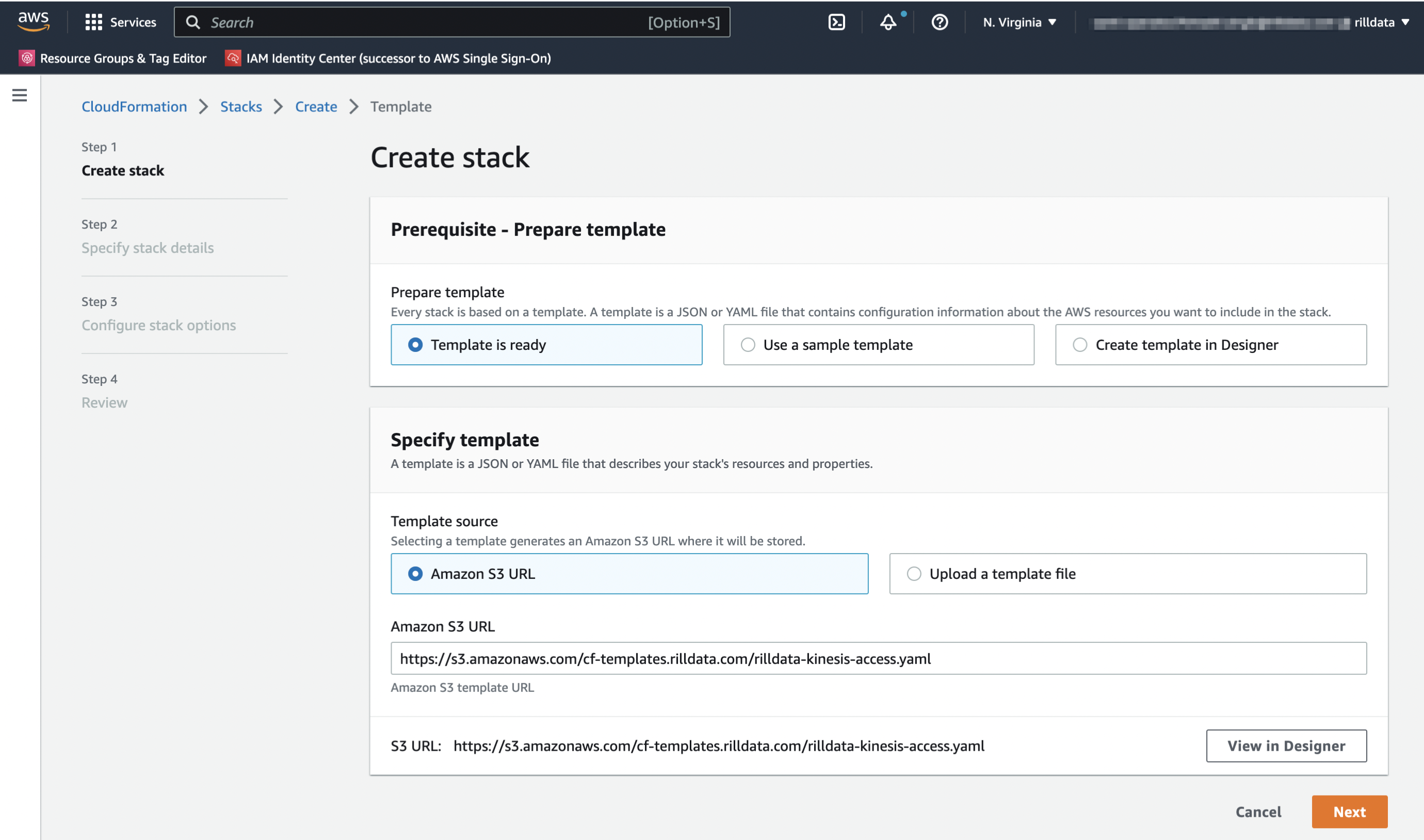
Specify Stack Details Stack Name:
rilldata-kinesis-accessKinesisARN: Name of the bucket we want to provide access to.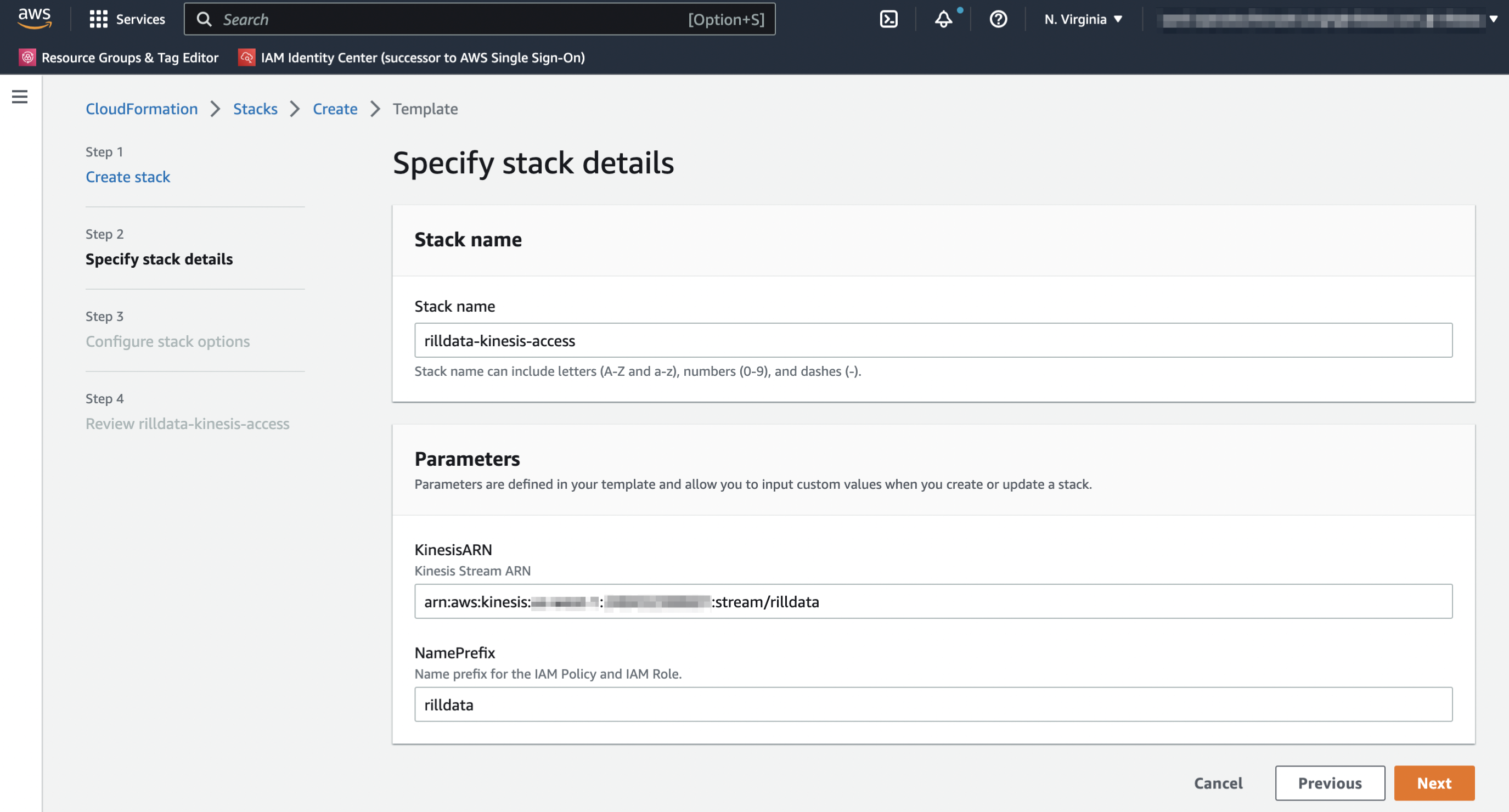
Click Next, Again Next, Acknowledge the Capabilities and Create the Stack.
You can check the events and it should create the resources for you.
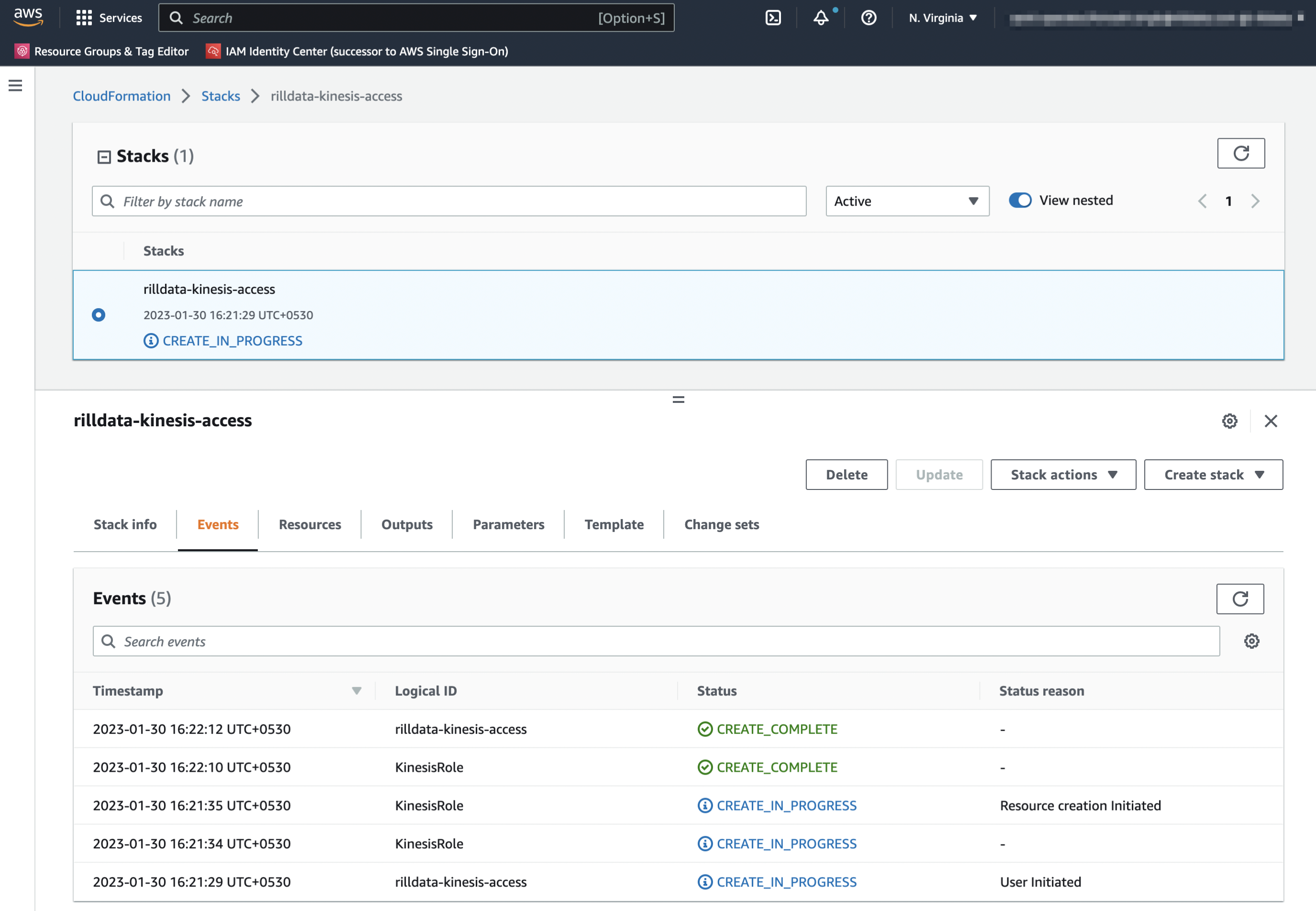
Share the Outputs with Rill Data
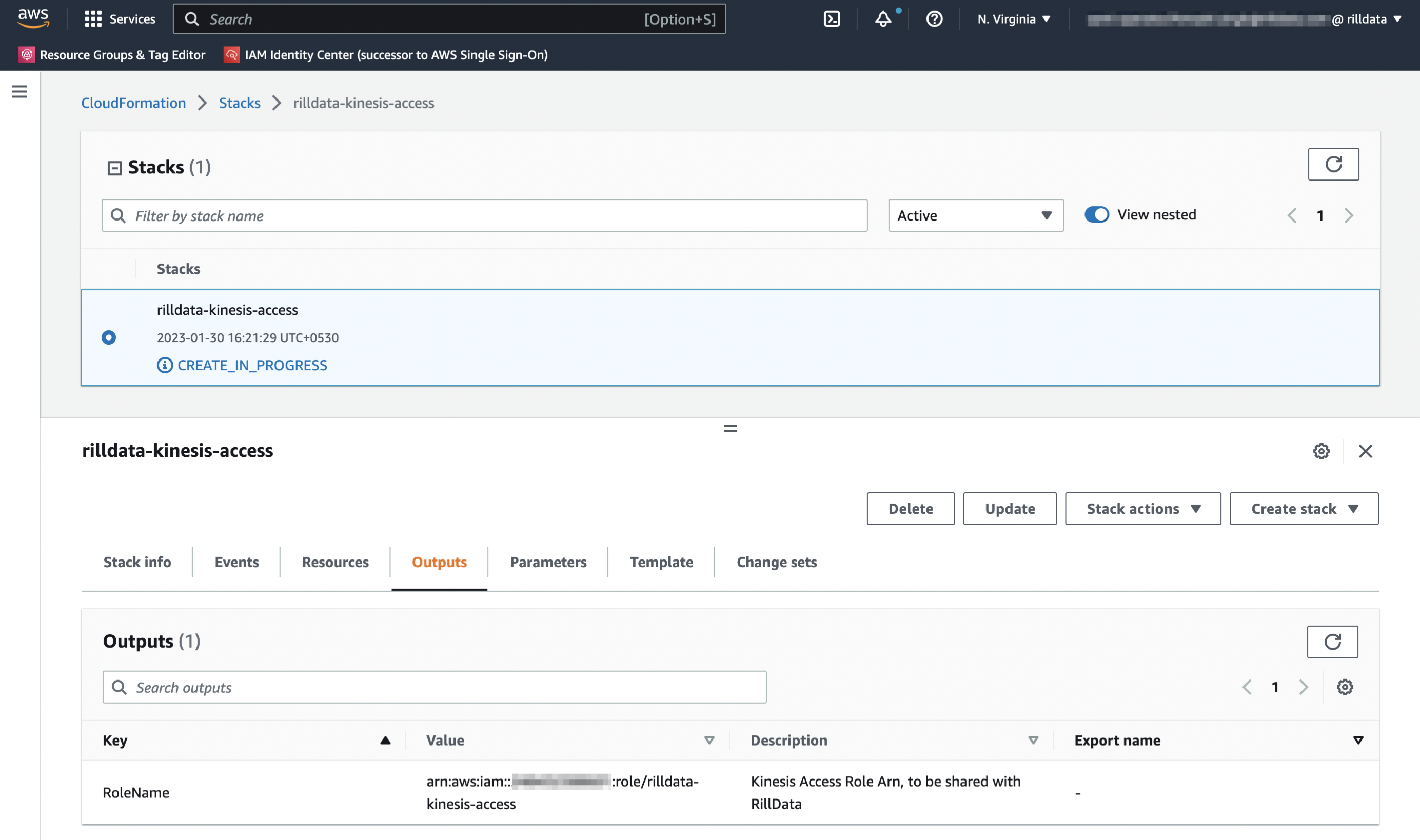
CloudFormation Template Reference
We would be using the following Cloudformation Template.
AWSTemplateFormatVersion: '2010-09-09'
Metadata:
License: Apache-2.0
Description: 'AWS CloudFormation Template for providing Rill Data Access to Kinesis. It creates a
Role that can be assumed by the RillData AWS Account. The Role has a IAM policy associated with them.'
Parameters:
KinesisARN:
Type: String
Description: Kinesis Stream ARN
NamePrefix:
Type: String
Description: Name prefix for the IAM Policy and IAM Role.
Default: rilldata
Resources:
KinesisRole:
Type: AWS::IAM::Role
Properties:
Description: 'RillData Access to the Kinesis. Managed by: Cloudformation'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
AWS:
- 'arn:aws:iam::248432388601:root'
Action:
- 'sts:AssumeRole'
Policies:
- PolicyName: !Join
- ''
- - !Ref NamePrefix
- 'KinesisAccessPolicy'
PolicyDocument:
Statement:
- Effect: Allow
Action:
- "kinesis:Describe*"
- "kinesis:List*"
- "kinesis:Get*"
Resource:
- !Ref KinesisARN
RoleName: !Join
- '-'
- - !Ref NamePrefix
- kinesis-access
Tags:
- Key: Accessor
Value: RillData
- Key: ManagedBy
Value: Cloudformation
Outputs:
RoleName:
Value: !GetAtt [KinesisRole, Arn]
Description: Kinesis Access Role Arn, to be shared with RillData
References
SSL Encryption
SSL uses private-key/certificates pairs which are used during the SSL handshake process.
- Each broker needs its own private-key/certificate pair, and the client uses the certificate to authenticate the broker
- Each logical client needs a private-key/certificate pair if client authentication is enabled, and the broker uses the certificate to authenticate the client
# Configure the password, truststore, and keystore
# Since this stores passwords directly in the broker configuration file,
# it is important to restrict access to these files via file system permissions.
ssl.truststore.location=/var/ssl/private/kafka.server.truststore.jks
ssl.truststore.password=test1234
ssl.keystore.location=/var/ssl/private/kafka.server.keystore.jks
ssl.keystore.password=test1234
ssl.key.password=test1234
# Enable SSL for inter-broker communication, add the following to the broker properties file (it defaults to PLAINTEXT):
security.inter.broker.protocol=SSL
Authorization
Kafka supports client authentication via SASL. SASL authentication can be enabled concurrently with SSL encryption. The supported SASL mechanisms are:
- GSSAPI (Kerberos)
- OAUTHBEARER
- SCRAM
- PLAIN
- Delegation Tokens
JAAS configurations
Kafka uses the Java Authentication and Authorization Service (JAAS) for SASL configuration. Provide JAAS configurations for all SASL authentication mechanisms. Brokers can configure JAAS by passing a static JAAS configuration file into the JVM using the java.security.auth.login.config property at runtime.
export KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf"
bin/kafka-server-start etc/kafka/server.properties
Brokers can also configure JAAS using the broker configuration property sasl.jaas.config. The prefix the property name with the listener prefix, including the SASL mechanism, i.e. listener.name.{listenerName}.{saslMechanism}.sasl.jaas.config.
Specify one login module in the config value. To configure multiple mechanisms on a listener, you must provide a separate config for each mechanism using the listener and mechanism prefix.
listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \\
username="admin" \\
password="admin-secret";
listener.name.sasl_ssl.plain.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \\
username="admin" \\
password="admin-secret" \\
user_admin="admin-secret" \\
user_alice="alice-secret";
This is the preferred method of configuring JAAS for brokers.
Authorization using ACLs
Kafka ships with a pluggable, out-of-box Authorizer implementation that uses ZooKeeper to store all the ACLs. It is important to set ACLs because otherwise access to resources is limited to super users when an Authorizer is configured. The default behavior is that if a resource has no associated ACLs, then no one is allowed to access the resource, except super users.
Broker Configuration
Authorizer
To enable ACLs, you must configure an Authorizer. Kafka provides a simple authorizer implementation, and to use it, you can add the following to server.properties:
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
Super Users
By default, if no resource patterns match a specific resource, then the resource has no associated ACLs, and therefore no one other than super users are allowed to access the resource. If you want to change that behavior, you can include the following in server.properties:
allow.everyone.if.no.acl.found=true
super.users=User:Bob;User:Alice